はじめに
前提
まず前提として、この記事を書いているのは未経験からプログラミングに挑戦中の者になります。学習はフィヨルドブートキャンプ(以下 FBC)に参加しながら取り組んでいて、現役のエンジニアの方からレビューをもらいながら進めています。
現在の学習状況は以下を随時更新しているので興味ある方はご覧ください。
hirano-vm4.hatenablog.com
今回は、チーム開発のプラクティスに入るにあたって「アジャイル開発/スクラム」について学習し、その内容をアウトプットしたいと思います。
注意点としてスクラムを実践したわけでなく、これから実践するにあたって書籍などで学んだこと、それを受けて個人的に感じた所感について書いた記事になりますのでお気をつけください。
アジャイル開発とは、システム開発の手法のひとつで、短いサイクルで開発とリリースを繰り返す開発手法のことを指します。
一度開発をしてリリースしたら終わりではなく、アジャイル開発ではリリースし、ユーザーからフィードバックを受け、それを優先順位に反映させて改善するというサイクルを短い期間で繰り返していく開発手法です。
また開発する単位にも特徴があります。アジャイル開発では、作成するシステムの単位を小規模な機能ごとに分割して、それぞれを企画からリリースまでを繰り返していきます。

各機能改善・追加のリリースごとに、 スプリント のサイクルを繰り返していきます。
イテレーションは、「計画」「設計」「実装」「テスト」の工程を反復することを指します。各機能の実装はこのサイクルを繰り返していきます。
私たちが現在使っているフィヨルドブートキャンプのWebアプリもアジャイルで開発されていて、毎週新しい機能がリリースされていることが確認できます。

また、私自身も普段利用しているアプリを使う際は、バグの改善・新しい機能の追加など日々機能が追加・改善される前提でサービスを利用していることに、この課題でアジャイルについて学んだことで気付かされました。
使っているアプリなどのアップデートの情報をみても、頻繁に更新されていることがわかります。
Google Chromeのアップデート履歴を確認してみた
このようにユーザーの意見などを取り入れてスピード感のある開発をしたい場合には、このアジャイル開発が向いています。
インターネットが普及する前のソフトウェア開発では、リリースすることがゴールとなってましたが、近年はインターネットやスマートフォンなどの通信端末の普及などもあって、リリース後のアップデートが可能になりました。
そのようなビジネス環境の変化もあって、現代は売り切って終わりでなく、サブスクリプション型へのビジネスモデルの変化がみられました。
このサブスクリプション型への変化は、ユーザーが気軽にサービスを利用できるようになった反面、逆にユーザーの求めるUXでない場合、すぐにサービスから離脱することに繋がります。
それを防ぐために、継続的に機能追加や改善をして、ユーザーに長くサービスを利用継続してもらうことが重要視されるようになりました。
「継続的な改善が前提」となっているアジャイル開発は、リリースしてからフィードバックを受けて、必要あれば優先順位を変更するなど、ユーザーのニーズを反映させやすい開発手法で注目されています。
アジャイル開発は、2001年にアメリカのソフトウェアエンジニアであるケント・ベックらがまとめた「アジャイルソフトウェア宣言」で示されています。

- プロセスやツールよりも個人と対話を、
- 包括的なドキュメントよりも動くソフトウェアを、
- 契約交渉よりも顧客との協調を、
- 計画に従うことよりも変化への対応を
このように左の青字のものにも価値があるとしつつも、アジャイル開発では右の赤字の 「個人との対話」「(ドキュメントよりも)動くソフトウェア」「顧客との協調」「変化への対応」 を大切にすると宣言されています。
この宣言から、まず小さくリリースして、動くものを見てからフィードバックをもらい、優先順位を設定して、プロダクトを改善していくという価値観であることが読み取れます。
留意しておかなければならないのは、赤字の概念が不要だと考えて「ドキュメントを作らない」「計画をせずに手を動かす」という意味ではないことです。
たとえ、アジャイル開発であっても計画やドキュメントも必要になる場面は存在します。
あくまで判断基準はアジャイル開発で重視する 「個人との対話」「(ドキュメントよりも)動くソフトウェア」「顧客との協調」「変化への対応」 であるが、それを実現するために、必要になるドキュメントや計画であれば、当然取り入れるべき というスタンスであるという理解を私はしました。
アジャイル開発はプロダクトだけでなく現場も変化する
アジャイル開発は、変化することを前提にしています。それは、プロダクトだけでなく 開発の進め方の変化も対象 としています。
開発してく中で、開発過程で課題があった場合プロセス自体も変化させていきます。
【例】
- メンバー同士の状況が把握できていないのであればタスクボードを取り入れる。
- コードレビューで戻りが多い課題があった場合、モブプログラミングを取り入れて齟齬を減らす
このように、一貫して同じことをするのでなく、開発過程で必要であれば、開発現場も変化していきます。
もちろん、一定の効果が得られたのでモブプロを一時中止するという判断も含まれます。
アジャイル開発では、開発の効率を高めるためにその都度、状況を把握して、その時々にあった形に開発方法も、プロダクトの機能追加の優先順位も変化していきます。
顧客が本当に欲しかったものにアプローチできる
ソフトウェア開発において「開発したけど使われない」「思っていたものと違った」となってしまう問題が往々として存在する。
ある調査によると完成した機能の60%は使われていないという結果も公表されています。
これがなぜ起こるのかというと、「利用者の課題を解決するもの」とずれてしまっていることが原因です。
「開発する側が考える需要」と、「利用者側が考える需要」は一致するとは限りません。
これはソフトウェア開発だけでなく、他の仕事であっても同様です。「クライアントの意見を聞かずに、自分だけの考えで資料を作って、クライアントに提案してみたら全く需要がなかった」なんて失敗はよくあるかと思います。
また、リリースされたものを見て意見が変化したり、時間とともに需要も変化することもあります。
アジャイル開発では、先述したように リリースし、ユーザーからフィードバックを受け、それを優先順位に反映させて改善するというサイクルを短い期間で繰り返していく開発手法 です。
そのためアジャイル開発は、 仕様変更・追加機能・優先順位の変化にも対応しやすい開発手法 だといえます。
また開発する側も、その都度コミュニケーションをとって意見交換をしながら開発ができるので、困りごとを共有しやすい環境になることもメリットになりそうだと個人的にも感じました。
スクラムは、アジャイル開発の手法の1つで、少人数のチームに分かれて短期間の開発サイクルをくり返し行うフレームワークのことを指します。
スクラムには以下のような特徴があります。
- ニーズを「価値」「リスク」「必要性」などを基準にして優先順位をつけて並び替えて、その順番で開発を進めることで成果を最大化する
- スクラムでは固定の短い時間に区切って作業を進める(タイムボックス)
- その時点での、現状や問題点を明らかにする(透明性)
- 定期的に進捗状況・期待されている成果が得られているか・進め方に問題はないかを確認する(検査)
- 問題があればやり方そのものも変化させる(適応)
このような特徴から、スクラムは わからないことが多い複雑な問題を扱うプロダクトに適した開発手法 といえます。
スクラムは, 5つのイベント(会議)構成・3つのロール(役割)・3つの制作物 などの最低限のルールで構成されています。
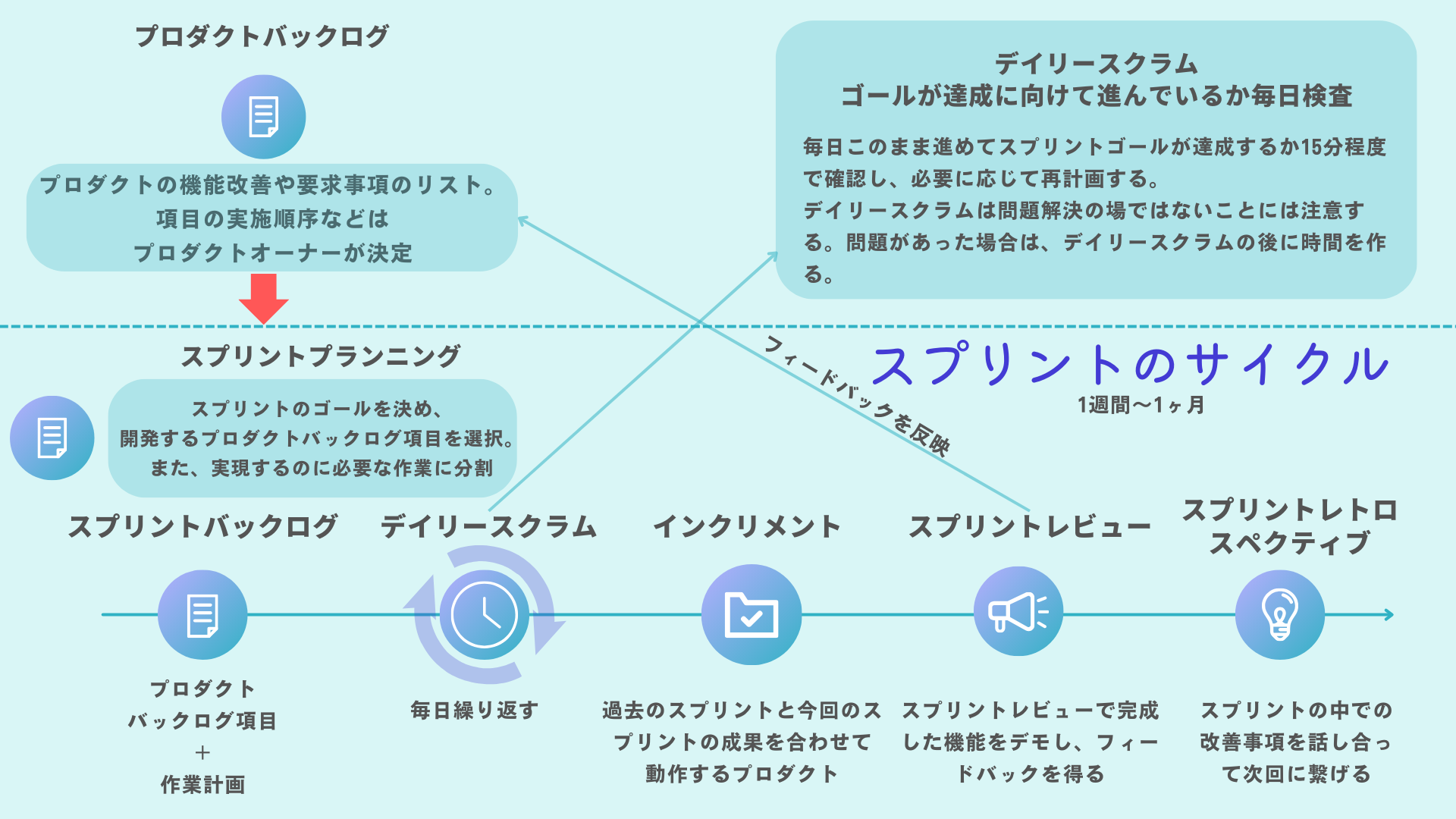
上記の画像にスクラムで必要とされる5つのイベントと3つの作成物の関係を可視化しました。
完成に向けて目標を細かな単位に設定し、それを毎回のサイクルに落とし込み、そのサイクル内で開発をしてレビューをして、フィードバックを次のサイクルに反映させて、を繰り返していきます。
小さい単位で開発と改善を繰り返すので、問題・課題が発生すれば開発体制を変更したり
、優先順位も入れ替わったりと柔軟に対応していきます。
これはよく言われるPDCAサイクルを回していくようなイメージだと私は捉えました。
スプリント
スクラムでは、通常1から4週間までの固定の期間で区切り、そのサイクルで開発を繰り返します。この期間のことを スプリント といいます。
スクラム開発におけるスプリントは、プロジェクトの進行を促進するための基本的な単位で、 この期間中にチームはプロダクトバックログから選ばれたアイテムを完了させる ことを目指します。
スプリントは、製品の迅速なリリースと、継続的な改善を可能にします。短い反復周期を通して、チームは製品の品質を維持しながら、顧客からのフィードバックを素早く取り入れることができます。
スプリントはチームに焦点とリズムをもたらし、透明性とコミュニケーションを促進します。
スプリントのような短いサイクルで、話し合う場面が設定されて区切りもあるので、開発する側にとっても悩みや困りごとを相談しやすい環境ですね。
まず、プリントを回していくにしても何をどの優先順位で取り掛かるかを定めなければ始まりません。
スクラムでは、 機能・要求・要望・修正などプロダクトに必要なものを抽出し順番に並べ替えたプロダクトバックログを作成 します。これは、1プロダクトにつき1つ作成されます。
プロダクトログのリストの順番は、その項目の価値やリスク、必要性などによって決定されます。上位にある項目がより重要度が高いものになります。
また、それぞれの項目は見積もられている必要があります。この 見積もりには時間や金額などの絶対値ではなく、作業量を相対的に表した値が用いられます。
このプロダクトバックログは一度完成したら終わりではなく、常に変化する要求や状況を反映して更新していく必要があります。それに伴って項目の順序も変化します。
スプリントを回し、スプリント終わりにフィードバックを反映させて、優先順位などの更新して次のスプリントに入ります。すべての始まりはプロダクトバックログから始まります。
そのためプロダクトログは 常に更新し続け、最新に保たなけばいけないもの です。
このプロダクトバックログから始まり、フィードバックもこのプロダクトバックログに返ってくると考えると、このスクラムにおいて非常に重要な役割を果たすことが、これまでの説明からも伺えます。
スプリントバックログ(スプリント計画)
プロダクトバックログの次は、 スプリントプランニング(スプリント計画) です。
スプリントを始めるにあったって、今回のスプリントで何をどれくらいまで作るのかを落とし込みます。
スプリント計画に使える時間は1ヶ月のスプリントの場合は8時間。スプリントの期間はそれよりも短い場合は、それに合わせて短くするのが通常です。
スプリントバックログで2つのトピックを扱う
1つ目は、 スプリントで何を達成するのかを決める ことです。
- 最初にプロダクトオーナー(後述)が今回のスプリントで達成したい目的を明らかにする
- 今回のスプリントでそれを達成するために完成させるプロダクトバックログ項目を選択
※選択する項目はプロダクトバックログの上位のものになるのが通常。また、選択する個数は各項目の見積もりサイズや開発の過去の実績(ベロシティ)、スプリントで使える時間を踏まえて仮決定
- 検討した内容を踏まえて今回のスプリントの目標を簡潔にまとめる(スプリントゴール)
開発チームがなぜここで選択したプロダクトバックログ項目を開発するのか理解しやすくなる。
このように、プロダクトバックログの上位から順に、今回のスプリントで開発する対象を選択するため、事前にプロダクトバックログの上位の項目については準備が必要です。
プロダクトバックログリファインメイト
プロダクトバックログの上位の項目の準備のことを「プロダクトバックログリファインメント」と言います。
- 項目の中身を具体的にする
- 項目の疑問を解決する
- 項目は何ができたら解決なのか(受け入れ基準)
- 項目を自分たちが扱えるサイズに分割する
- 項目を相対的に見積もる etc
やはり、プロダクトバックログの説明の最後に書いたように、プロダクトバックログが最初の起点であり、重要であることがこの説明からもわかりますね。
②開発チームがどうやって選択したプロダクトバックログ項目を実現するか
2つ目は、「開発チームがどうやって選択したプロダクトバックログ項目を実現するか」について計画を立てます。
選択した項目ごとに具体的な作業を洗い出すなどをして作業計画を立てます。
スプリントバックログ
選択したプロダクトバックログ項目と作業の一覧を合わせて スプリントバックログ と言います。
スプリントバックログは 開発チームの開発計画であり、スプリント期間中も自由に作業を追加したり削除することができるものです。
ちなみに、ここの作業については1日以内で終わるように分割するのが一般的な方法です。難しい状況があればプロダクトオーナーと相談し、項目を調整したり、計画を見直すなどの調整を行います。
注意しなければいけないのは、開発チームはスプリントプランニングで決定した方針を完遂するよう全力を尽くす必要はあるが、計画したことを全て完成させることを約束しているわけではない、ということです。
すべての完成を約束してしまうと、見積もりが外れる、難易度が高かったり、不測の事態が起こったりした際に、開発チームが長時間残業になってしまったり、必要な作業を省くなどの問題につながる可能性がある。
この部分については、近年、納期とノルマを遵守を求めるあまりに商品の品質に問題が発生したり、不正につながる事件が起きていることを考えると想像がしやすいと感じました。
もちろん守れる技術力を磨くことは重要ですが、難しい時に相談しやすい雰囲気や関係性、柔軟な方向修正も長い目線でめると重要だと感じますね。
デイリースクラムはスプリントの中で、毎日行われる短いミーティングのことを指します。チームメンバーが何に取り組んでいるか、何か問題はないかを共有し、ゴールの達成に向けて進んでいるか毎日検査します。
デイリースクラムは、開発チームの人数に関係なく15分間のタイムボックスで行い、延長はしません。
デイリースクラムはの進め方は特に決まりはないが以下の点について確認することが多い。
- スプリントゴール達成のために、自分が機能やったことは?
- スプリントゴールを達成するために、自分が今日やることは?
- スプリントゴールを達成する上で、障害になることはあるか?
このようなことを共有して、スプリントがゴールに近づいているかを確認します。確認するだけでなく場合によっては、メンバー間で協力したり、方法を変えるなどの修正をしていきます。
注意しなければいけないのは、デイリースクラム自体は問題解決の場面ではないということです。問題を把握し、対処が必要な場合は、デイリースクラム終了後に時間を作って、必要な人で別途相談の場を設定します。
あくまで15分というタイムボックスは守ります。これは現在地を確認し、問題があれば把握するという役割がデイリースクラムにはあるということだと思います。
インクリメント
ここからスプリントの終わりに向かっての流れの話になっていきます。
スクラムでは、スプリント単位で評価可能なインクリメントを作ることが求められます。
インクリメントとは、過去に作ったものと、今回のスプリントで完成したプロダクトバックログ項目を合わせたものです。
多くの場合は、動作するものとして提供され、スプリント終了時点で完成していて、正常に動かなかればいけません。
そのため、プロダクトオーナーと開発チームが「完成」と考える基準を共有していなかればいけません。この基準のことを「完成の定義」と呼びます。
開発チームはこの基準の定義を満たすプロダクトを開発しなければなりません。
この完成の定義を擦り合わせておかないと、双方の基準がズレるということがよくあるのはどの業界の仕事にこいても重要なことなのでイメージしやすいかと思います。
ちなみに、この完成の定義は「品質基準」とも言い換えることができます。
スプリントレビュー
スプリントレビューは、プロダクトオーナー主催でスプリントの終わりに行われるミーティングです。スプリントで完成した製品のデモを行い、ステークホルダーからのフィードバックを受け取ります。
この フィードバックが最大の目的 です。
スプリントレビューでは、開発チームがスプリント中に完成させたインクリメントを実際にデモします。これは、プレゼンテーションによる説明ではなく、実際に動作する環境を見せながら確認 できるようにします。
動かしながら説明し、場合によって実際に触ってもらってフィードバックを引き出します。
実際に動作する環境を見せながらの確認は、実際に画面を見て、動かしてもらうことで開発チームとステークホルダーなどの方向性のずれの修正や、間違っていないことが確認できる重要な場面だと感じますね。
スクラムのように短い期間でそのような機会があるということが大きなずれになる前に修正もしやすくなり、スクラム開発の大きなメリットの一つであることが学習していても想像できた部分でした。
ちなみに、このスプリントレビューでデモすることができるのは当然、完成したものだけです。
そのためスプリントレビューの前までに完成したプロダクトバックログと、そうでないものを整理しておくのが一般的と言われています。
また、その上でデモを行い以下の点についてスプリントレビューで報告・議論します。
- スプリントで完成しなかった項目を説明
- うまくいかなかったことやその問題点、解決した方法について議論する
- プロダクトオーナーがプロダクトの状況やビジネス環境について説明する
- プロダクトバックログに追加するべき項目がないかを確認する
- 今後開発していく上で問題となる点を確認する
- 現状の進捗を踏まえてリリース日や完了日を予測
この議論で得た内容は、必要に応じてプロダクトバックログに反映します。
ここで得た内容がプロダクトバックログに反映されるので起点はやはりプロダクトバックログです。毎回のスプリントの内容が反映されて、最新の状態をもとに次のスプリントに入っていくことになり、良い循環が生まれるのだと思います。
ちなみに、スプリントレビューに使える時間は、1ヶ月スプリントであれば4時間、スプリントがそれよりも短い場合はそれに応じて短くするのが一般的と言われています。
スプリントレトロスペクティブ
スプリントレトロスペクティブは、スプリントの終わりに行われる最後のミーティングで、チームがスプリントの過程を振り返り、改善点を議論します。
- まっとうまく仕事を進める方法はないか検討し、改善を繰り返す
- バグの修正では、バグが発生する原因を探る
- 人、関係、プロセス、ツールなどの観点で今回のスプリントを検査する
- 今回うまくいったこと、今後の改善点を整理
- 今後のアクションプランをつくる
- 一度にたくさんのことを変更しようとしない
このように毎回の短いスプリントの期間で良い部分と改善点を認識し、修正していくことができるのはスクラムのメリットだと感じます。悪い部分だけでなく、良い部分を認識するという点についても個人的には魅力に感じました。
ちなみにこのスプリントレトロスペクティブに使える時間は、1ヶ月のスプリントの場合で3時間程度で調整します。
この項目ではスクラム開発に登場する登場人物をそれぞれ解説します。
プロダクトオーナー
プロダクト製品のビジョンを持ち、プロダクトバックログを管理する役割を担う責任者をプロダクトオーナー(PO)と呼びます。1つのプロダクトにつき1人設定し、プロダクトバックログの項目の並び順の最終決定権を持ちます。
プロダクトのWhatを担当し、ステークホルダーとチームの間でコミュニケーションを取り、製品の価値を最大化します。プロダクトバックログが完成しているか確認も行います。
しかし、プロダクトオーナーは開発チームに相談はできますが干渉はできません。
製品の価値を最大化する責任があるのためプロダクトバックログの項目の並び順を決定する以外に以下のような仕事も行います
- プロダクトのビジョンを明確に持ち、周囲と共有
- おおよそのリリース計画を定める
- 予算を管理する
- 顧客・プロダクトの利用者や組織の関連部署などの関係者と、プロダクトバックログの項目の内容を確認したり、順番、リリース時期を相談調整する
- 既存のプロダクトバックログの内容を最新の状態にする
- 関係者がプロダクトバックログについて理解できるように働きかける
- プロダクトバックログが完成しているか確認する
プロダクトバックログの管理は開発チームと行うこともあるが、最終決定はあくまでPOが行います。これは、POが最終決定することで結果に対してPOが責任を持てることにつながります。
開発チーム
開発チームの主な役割は、プロダクトオーナーが順位付けしたプロダクトバックログの項目を順番に開発することです。
開発チームは通常3〜9名程度で構成され、3人未満の場合は、お互いの相互作用が少なかったり、個人のスキルに依存することが多くなてしまうため、スクラムでは推奨されていません。逆に10人以上になるとコミュニケーションコストが上がることで効率が落ちると言われています。
デザイナー、プログラマー、テスターなど、製品開発に必要なスキルを持つメンバーで構成され、肩書きやサブチームはありません。
スキルに差がある場合もありますが、作業を進めていく過程でなるべく個人が複数のことができるようになることが望ましいと言われています。
この部分に関してはチームの各メンバーの得意、不得意を把握して、「適材適所に人を割り当てる場面」「スキルの幅を増やすためにあえて挑戦する場面」の両面を意識して、チームを運営していく必要があるのだと想像しました。
開発チームの仕事の進め方は、開発チームのメンバーの合意のもとで進められ、外部から作業の進め方を指示されることはありません、プロダクトオーナーの部分で、「開発チームに相談はできるが、干渉はできない」と説明したのはこの部分になります。
あくまで開発チームは全体で責任を持って作業をすすめ、これを 自己組織化 と呼びます。開発チームが主体的に進めることで、開発チームの能力は継続的に向上していくことにつながります。
スクラムマスターは、スクラムプロセスがスムーズに進むよう支援し、チームの障害を取り除く役割。チームが高いパフォーマンスを発揮できるように促します。
プロダクトバックログをプロダクトオーナーが並び替え、開発チームがそれをもとに開発を進めます。そのプロセスを円滑にまわして、プロダクトを効率よくつくれるように支える役割が スクラムマスター です。
まさに「縁の下の力持ち」の存在だと言えます。
- 仕組みがうまく回るように支援する
- 障害の排除
- 支援と奉仕
- 教育・ファシリテーター・コーチ・進行役
- マネージャーや管理者ではない(タスクのアサインも進捗管理もしない)
スクラムマスターは、ルールや作成物、進め方をPOや開発チームに理解させ、効率的な実勢を促しながら、スクラム外にいる人からの妨害や割り込みからチームを守ります。
チームがまだ、慣れていない間には、やり方を教える・イベントの司会進行をするなどトレーナー的な動きもしたりもします。チームの求めに応じて作業を助けたり、ヒントを与えるなどの動きも含まれるなど多岐にわたります。
スクラムマスターの動きの一例
- PO・開発チームにアジャイル・スクラムについて理解できるよう支援する
- (必要時)スプリントプランニングやスプリントレトロスペクティブなどの司会進行
- POと開発チームとの会話を促す
- 生産性を高めるためにチーム・POに働きかける
- プロダクトバックログなどの良い管理方法を提案する
スクラムマスターの役割は、チームの潤滑油的な役割を果たすポジションであることが伺えます。
想像するに、どうしてもプロダクトオーナーは開発の進行状況が気になり、開発チームは進行を気にしながらも開発で問題があると視野が狭くなり、チームだけでは問題を認識できない場面や、解決が難しいがでてくることが想像されます。
そんな場面でスクラムマスターが俯瞰してチーム全体を見て、うまくチームが回るように気づきを与えたり、改善を促すような提案をするなどの役割・立ち回りが必要なんだと感じました。
ここまででてきた、「プロダクトオーナー」「開発チーム」「スクラムマスター」を合わせて スクラムチーム と呼びます。
スクラムを活用して良い結果を生むには、スクラムの5つの価値順を取り入れて実践していく必要があると言われています。
- 確約:それぞれがゴールの達成に全力を尽くすことを確約する
- 勇気:正しいことをする勇気を持ち、困難な問題に取り組む
- 集中:全員がスプリントでの作業やゴールの達成に集中する
- 公開:すべての仕事や問題を公開することに合意する
- 尊敬:お互いを能力のある個人として尊重する
スクラムのフレームワークを実行するだけでなく、それを効率よく活用するにはこれらの価値基準を踏まえて各個人が行動することが大切だと書かれています。
やはりどんな素晴らしいフレームワークであっても、人がフレームワークを活用します。
意見・相談を言いやすい雰囲気、チームで協力する姿勢、お互いをリスペクト持つなどのチーム状況でなければチームは成果をうまく出せないと思います。
スクラムのメリットを最大化し、良い成果を出すために、土台になる価値基準になると思うので、私自身しっかりを確認してチーム開発に臨みたいと思います。




